

A larger portion of this has been written in bits, and pieces scattered around note-taking apps, paper, and scattered pages in my room. I want America and the West to “win”, or at the very least, stop making the most moronic decisions humanly possible on a consistent basis, and moreover lately, stop listening to influencers. At a personal level, if you “listen” to the loudest voices, you will pay a small price, but at a national level ? You are influencing geopolitical, non-linear dynamics and “shifting” the path of history.
Any person with some applied mathematics proficiency (a term encompassing Linear Algebra, Probability, Statistics, Calculus, Optimization Theory, Information Theory, etc, all very important for Machine Learning, especially the first 4), or a passion for Machine Learning would look at Large Language Models architecture and training methods and scream how inefficient it is. It is not just energy inefficient, but its training (learning), data structure, etc.
You can easily counter that via resource abundance. Resource abundance will often lead to poor optimization, intellectual laziness, and overall a bad habit of “brute forcing” your way into results, and this can be observed everywhere, war, industry, you name it. This was the most self-evident in the case of OpenAI’s ChatGPT, Anthropic’s Claude, Microsoft Copilot, and a few other smaller players.
These companies and their CEOs became what is now referred to as “hyperscalers” a term born from the Machine Learning belief that Scale is All You Need, meaning you can achieve and surpass human intelligence by merely scaling hardware up, training bigger models, with more data. If you scale enough you can brute force your way into better results, at a significant economic cost. Before explaining anything further, we need a “deep lore”.
Most of OpenAI’s higher talent came from Google’s DeepMind. Anthropic ? Former OpenAI and former DeepMind. France leading lab, Mistral ? Former DeepMind. Japan’s leading AI lab, Sakana ? Former DeepMind. The Transformer architecture, the one powering Large Language Models was created by DeepMind. Although the belief that scaling laws are old, they regained new life with LLM’s, and the meme was somewhat born from DeepMind, but made completely viral by its “satellites” (I consider all these labs satellites of DM).
And that is what OpenAI, Anthropic, and DeepMind sold to the world, you need to scale. You need more GPUs. You need more hardware. You need data centers that can be seen from the stratosphere. You need nuclear power to feed these behemoths of energy and water. In the sea of non-linear dynamics and unseen trends, the only reason the American economy has been propped up in the past 2 years was exactly this.

Brute force scaling didn’t become dominant by accident—it was the path of least resistance. In a field where real theoretical breakthroughs are scarce and progress is measured in benchmarks, the easiest way to stay ahead is to throw more hardware and data at the problem. Faster time-to-market beats intellectual elegance every time when billions are on the line. Why spend years developing a more efficient algorithm when you can just stack more GPUs and get a slightly better model now? That’s the mentality that took over.
A positive feedback loop, where all these companies rely on Nvidia, the world’s leading GPU developer, leads to more capital being spent, which gets you more investment, and repeats the cycle. After all, brute forcing your way into results worked so far, scale is all you need. On the other side, the heavily criticized (by me) “Chips ban”.
The Law of Unintended Consequences
It doesn’t take a genius to see how the chips ban would backfire within a year or two, it just takes you reading about the Chinese tech industry, and how large it is, and spending a few days reading the most recent STEM papers, especially physics and mathematics. A large portion of science and scientific breakthroughs are made by Chinese or scientists of Chinese descent, with China leading math in the entire world.
While you can do Machine Learning without having an absurdly deep understanding of mathematics, it is a mathematical field, one that can drastically improve by algorithmic improvements, and efficiency gains from optimization, all derived from…math. If you force resource containment on an adversary, he is bound to get creative… after all, necessity is the mother of all inventions.

Enter my favorite AI lab for the better part of the last 18 months. DeepSeek, known in Machine Learning niche circles as “Whale bros”. By now even your grandma has heard the name “DeepSeek, that Chinese AI company that made a cheap ChatGPT”.
I have eagerly followed DeepSeek for a long time and kept my eye on each paper they published. A small investment quant (quants go extremely hard on math and optimization) started by a gifted nerd that had the goal of creating AI, and after ChatGPT exploded, had idle GPUs to spare and start its side-project.
DS was a sort of a small joke among the big boys in China (Alibaba, BytaDance, etc), its CEO isn’t a PhD, it is not from a prestigious university inside China, never studied abroad (US), and particularly quiet and low-key, the Chinese public for the most part never heard of DS. Its hiring policy is fairly distinct from everywhere else, China, the US, or Europe (it doesn’t hire ONLY PhDs such as Silicon Valley). Its funding structure is unorthodox. An odd, small company to say the least.

DS's rise to stardom was a long time coming and it wasn’t a surprise if you spent time reading their papers and heavily using or testing their models.
The first sign of a remarkable breakthrough in the making was their paper DeepSeek Math, where they introduced GRPO, a reinforcement learning (RL) algorithm specifically created (by them) to improve reasoning capabilities in LLMs. Reasoning is a fancy tech term for “thinking through steps and learning along the way”, it increases the quality of outputs (answers to your questions/prompts).
GRPO diverges from normal RL because it is orders of magnitude more efficient than normal RL (which relies either on humans, or other models acting as critics), it is far cheaper because you don’t rely on annotated data (data that is tagged, added description and whatever else needed so Machine Learning models can understand it with more ease and learn from it). The annotation industry is a billions dollar industry, until last week, the entire ecosystem relied on it.
GRPO is also significantly less compute-intensive, it doesn’t need as many GPUs as ChatGPT, or Claude. The second breakthrough, built upon the first was DeepSeek R1 lite.
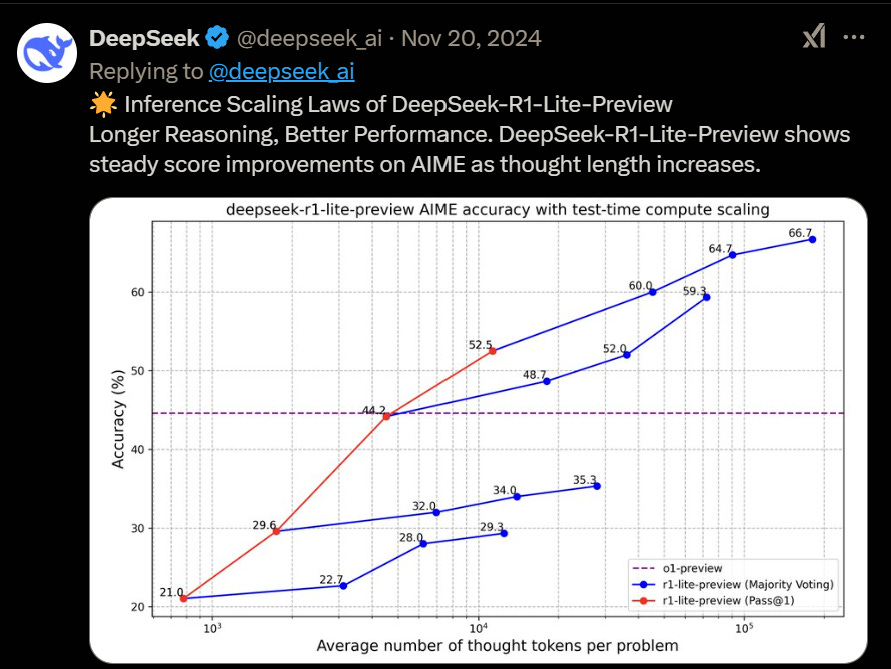
The next step was DeepSeek V3, their “actual” breakthrough, with all the innovations put together from DS Math, and from scaling R1 Lite, V3 presented a paradigm shift in LLM training, it had yet new breakthroughs, it took 2 months to train and the training cost of the model was 5 million dollars. Yes, that is not a bogus cost that a lot of influencers and CEO’s are crying about, the model training cost 5 million, but this doesn’t take into account everything else.
The model everyone is using and reached virality beyond understanding was built upon all these findings, all this hard work, algorithmic innovation, and crazy levels of smart engineering and optimization. DeepSeek R1. The silent whale made its seismic impact.
Why the Whale made such a impact ? Simply put, it is open source. Except for their data which they spent over a year carefully curating, building, and structuring, everything else is open source, and public. Unlike its competitor’s black boxes, DeepSeek made all its breakthroughs public, and well documented, so any other AI lab or person can replicate it, and they did, from a small scale costing 30 dollars, to now larger scale trying to replicate the full model.
Does your model lack Reasoning ? You can use their approach to introduce powerful reasoning to your model ? Is your model a behemoth of inefficiency ? You can use their algorithms to train more efficient, faster models. You can apply all of their findings to improve your own products. Above all else, you can download their model and do whatever you want with it.
Use it, improve it, fine-tune it (improve the model performance into specific tasks or fields of knowledge you need), build on it, over it. Anyone is free to do whatever they want with the model and the knowledge because it is open. It pushed the entire world into a better, more advanced, and fairer place. XAI just added Reasoning to Grok 3 (clearly, and obviously built and based upon R1 and DeepSeek breakthroughs), Meta is dissecting every line of DS paper and model to add to their model and every company will benefit. GPU-poor academics already love R1.
Don’t take my word for it, you can read Intel’s CEO Pat Gelsinger's words.
DeepSeek is an incredible piece of engineering that will usher in greater adoption of AI. It will help reset the industry in its view of Open innovation. It took a highly constrained team from China to remind us all of these fundamental lessons of computing history.
DeepSeek has dominated the minds and social media feeds for days, which is a shame, because this wasn’t a one-off, it wasn’t lucky, it wasn’t IP theft, and it is easy to prove. Independently from DeepSeek, another “small” Chinese startup launched an absurdly strong model.
Moonshot’s Kimi AI, built far cheaper than its American counterparts, independently from DeepSeek findings (it uses the “expensive, and complex RL”), is multi-modal, meaning it can read text, images, PDFs, and reason between them. I was incredibly surprised after testing for hours how strong the model is (it is not as smart or has the “soul” of R1, but it is crazy strong), it easily equates to GPT 4o and Claude Sonnet. Adding salt to injury, it has unlimited use.
2 days after DeepSeek R1 launch, TikTok owner ByteDance one of the leading AI companies in China, launched Doubao 1.5 Pro, capable of reasoning such as R1. I would expect Alibaba’s Qwen to soon have a Reasoning release too, and they just release a base model that is as strong as DeepSeek V3, open source too.
I am bringing these to your attention because, besides small ML/AI circles or China (ByteDance Doubao and Qwen are big in China), there are other companies making strides in advancing AI research. None as impactful as DeepSeek. And there lies the heart of our problem, the memetic virality of DS R1 was so strong, it grew so fast, like a virtual pandemic that it wiped 1 trillion dollars out of the stock market out of fear.
Thus we are back at step 1 — banning and restricting chip export to China, but for whatever reason people’s memories are failing, their reasoning degrading, their long-term thinking, and second and third-order analysis suffering loss. Biden’s chip ban had two-fold effect:
What you just read, algorithmic innovation, amazing engineering
Pushing China toward technological independence much faster than one would want
DeepSeek may have been trained in a few thousand Nvidia GPUs, but its inference (actual real-world use, for any task, like you asking the AI something) is being done on Huwaei Ascend chip 910C, which is not as strong as Nvidia’s H100, but was optimized to run DS it pretty well.

It will be hard for Huawei to meet the demand this year, but now DeepSeek is China’s darling, and why this matters ? In one of its papers, they leave directions for chip manufacturing and optimization so they can train and offer inference faster, and better, without relying on Western chips, without naming names. The Chinese government will now tell Huawei to do whatever form of customization DS needs, and they will foot the bill.
Shortly after DS went viral, the Bank of China announced the injection of 137 billion dollars over the next 5 years for the AI race. We have yet to witness what the Chinese government will do, now that they woke up and decided to participate in the AI race. Here is DeepSeek CEO (right) meeting Li Qiang, China’s number 2 (left).

We have more than a chance to retain AI dominance and win the AI race, but if it abides by sheer, pitiful protectionism of inefficient companies such as OpenAI and Anthropic, both CEOs acting like petulant children, and listening to loud voices of economic warfare, they will push China even faster towards more integrated technological independence.
The West should embrace what built its technological dominance, innovation, playing smart, open source software, otherwise, there is a real risk of being outpaced and being permanently behind its biggest adversary. After all, in the end, it goes down to numbers, and China has introduced more STEM workers in 5 years, than we have in total.
One equation and a few new innovative algorithms caused all of this. Bear that in mind every day.
This section is called The Fourth Option for a reason, besides an internal joke between me and my friend First Contact.
As always, thank you so much for your continued support !

I just felt like writing it, and I write what I feel like (wow, remarkable lol). Normal one coming soon.
Great post, great considerations and reportage! Thank you so much, a breath of fresh air in the smoke and dust cloud many have raised not accidentally...