
DeepSeek's Seismic Shift
Charting the Mariana Trench of efficinecy and optimization

I have been waiting a while to write a sequential article to my last one, here in The Fourth Option. While this is an article centered both on DeepSeek and the wider geopolitical repercussions of what they did in January and this week, it will also focus on the mind behind it all. Liang Wenfeng. A trivia.
The DeepSeek logo is not any whale. It is a Killer Whale.

As a Whale (the now largely recognized slang to refer to the Frontier AI lab DeepSeek) enthusiast, I knew they would respond to the highly copium-enfused response to the release of their foundational reasoning model and its subsequent open sourcing. After all, 200 people with a company spending a few million dollars can’t beat the hordes of (useless) PhDs in Silicon Valley, haha.
The outright lies were many, from being a CCP spying ops to being a heavily subsidized operation by the Chinese government burning hundreds of millions of dollars to having 50.000 smuggled GPUs to train its groundbreaking model and outright lying about everything as a ploy to… whatever moronic. This last lie is my most egregious and automatic IQ test from my perspective, which many failed.
Liang Wenfeng is a singular founder, being very distinct from the common, somewhat carbon copy Silicon Valley/YC founding mill. With just a web search, you can find a few of his interviews, and if you decide to read them, you must take them at face value because that is the type of person Wenfeng is. Besides the aforementioned hiring practices and his education history, there is another variable to add to this equation.
DeepSeek's Chief Infrastructure Engineer lamented not listening to Wenfeng after the colossal successful launch of R1, and you may ask why. Because he made their conversation pre-launch public. Wenfeng asked the CIE what his estimation was for how many servers they would need to launch R1 and be able to deal with any surge in demand.
10 to 20 servers would suffice. Wenfeng replied, “80 sounds good”, but left the choice to his engineer, who argued that maintaining 80 servers, mostly without use, would cost millions of dollars. Days after the launch, he stated he should have listened to Wenfeng. A common byproduct of founding a quant hedge fund (an investment firm that focuses on using algorithms and artificial intelligence) is becoming a “maximum efficientialist”, Wenfeng and many of his team clearly being one. In quant trading, efficiency is a competitive edge and money; loss of efficiency = financial loss.
I left a few clues weeks ago in one of my articles where I stated, “perhaps everything is data and data is everything,” alluding to the importance of data, and this is another Wenfeng differential. The whole firm prioritizes highly precise data labelling, with employees publicly sharing that Wenfeng himself would spend days and nights labelling data. An example of data labelling is below.
Data labelling and annotation is a billions-dollar industry, as mentioned in the last article, but high-quality labelling and annotation takes longer and is even more expensive because high-quality annotation relies on field experts. Do you want high-quality labeling and annotation for biology ? You pay a couple dozen PhDs hundreds of dollars per hour, repeat for each field.
This helps machine learning and the models to understand and learn from the data with better efficiency, which equates to a “smarter” model, among other variables. This is the most boring, and “soul sucking” part of Machine Learning. In the end, high-quality, uniquely structured labeling and annotation ends up giving you significant gains on your task.

Wenfeng has been a data sommelier longer than most, since he and his friend were gathering data during the 2008 crash to test if you could use algorithms and machine learning to predict market behavior. It became a recurring joke among certain circles on Twitter to poke fun at OpenAI for being the closest source AI lab on the planet. Many Whale employees poked fun at OAI, but the company was never vocal until now.
Thus came the Whale response to all the cope and tears birthed from the DeepSeek R1 release. And unbeknownst to most, it is more impactful than their open sourcing of an extremely competent reasoning (thinking) model. DS suddenly announced “Open Source Week”, where they would open source parts of their stack, specific software, infrastructure details, algorithms, and code that made the company what it is.
The Open Source Week

Day 1, they open source their innovative breakthrough Flash MLA, a highly efficient way to reduce memory consumption (which is a hog in other models) by an average of 50%, breaking the data in smaller pieces and working on it smarter (not harder…heh). Their method is specially tailored to H800, an enterprise GPU that is weaker than the widely used H100, and they achieve 8x gains over the industry average. This makes offering inference (whenever you ask an AI model something or it does some task) significantly cheaper.
Day 2, DeepEP, another efficiency gain in both training and inference of the Mixture of Experts (MoE) part of the model, and using Expert Parallelism. MoE, in simplistic terms, is designing “chunks” of a Large Language Model to be “smart” in specific fields. The “answers” AI provides you increase in quality, but there is an efficiency trade-off. By making the “experts” communicate in parallel and faster, and by the model choosing the best experts, you need less compute (GPUs) while achieving increased performance.
Day 3, DeepGEMM. 300 lines of code, with an extremely simple implementation, dependency-free, achieving highly efficient and precise calculation using a lower-precision format. This means they effectively achieved higher precision and higher efficiency, reduced memory usage, and obtained faster results using a lower-precision method.
Day 4, Optimized Parallelism Strategies. The first boom. This was a full release of their approach to pipeline parallelism, a way to break the training of a language model into a bunch of pieces and handling multiple parts at once. It minimizes idle time during training, making absolutely sure every single GPU is running (this is a big problem in ML), and achieves full overlap in the training phases (forward, backward), assuring the aforementioned step.
This makes training models more efficient, faster, with fewer errors, and using fewer GPUs. If you click that link and read who created this, one of the authors of this breakthrough is Liang Wenfeng.
Day 5, 3FS. The second boom. One of the biggest surprises to everyone paying attention to their releases. A proprietary (although built on another open source software) data filing system. They achieve unbelievable data reading and transferring speeds, achieving 6.6 TiB/s read throughput in a 180-node cluster. It considerably lowers the wait times for model training, given that the model can access data simultaneously from anywhere in the system almost instantly.
Worth noting this AI-centered highly efficient file system didn’t materialize from thin air, but it is a 6-year old project from their quant fund.
It makes training faster and inference better and faster, and it can handle massive datasets and scaling without problems. To understand this part, let me put it in financial terms. If DS decided to repackage this as a proprietary filing system and sell it, they would make billions of dollars on it alone. DS is not an accident; it didn’t occur by chance, and neither does its success. There is room for the argument on its meteoric rise being accidental, a product of going viral.
I have my doubts about the accidental nature of this event. As I commented to my friend First Contact Newsletter weeks ago, even if I am just 50% correct in my assessment of Wenfeng, it is already dire for us in the West. I have met a handful of Wenfeng’s in my life, and the only way they don’t have outsized impact in human society is by deciding not to.
Open-sourcing these steps will benefit the entire world, achieving significant efficiency gains and lower resource consumption, energy consumption, and training costs. Enacting one of the most sophisticated technology proliferation events in modern history. At this point, they proved every one of its critics (and grifters) wrong while providing invaluable knowledge and flexing their superior skills at the same time, but there was still room for doubt among the skeptical.

The orbital bombardment
DeepSeek has an internal saying among some of its employees. “The Whale moves slowly, but its impact is seismic.” On Day 6, they had One More thing to say. What a few instantly recognized as either a nuke, but it is more akin to an orbital bombardment.
DeepSeek made their Inference system stack public. An overview of how their infrastructure is set up, how many tokens they serve, how many GPU’s they use, how much each GPU produces token-wise, alongside a detailed peer into their entire inference business infrastructure and how much money they spend and how much they earn.
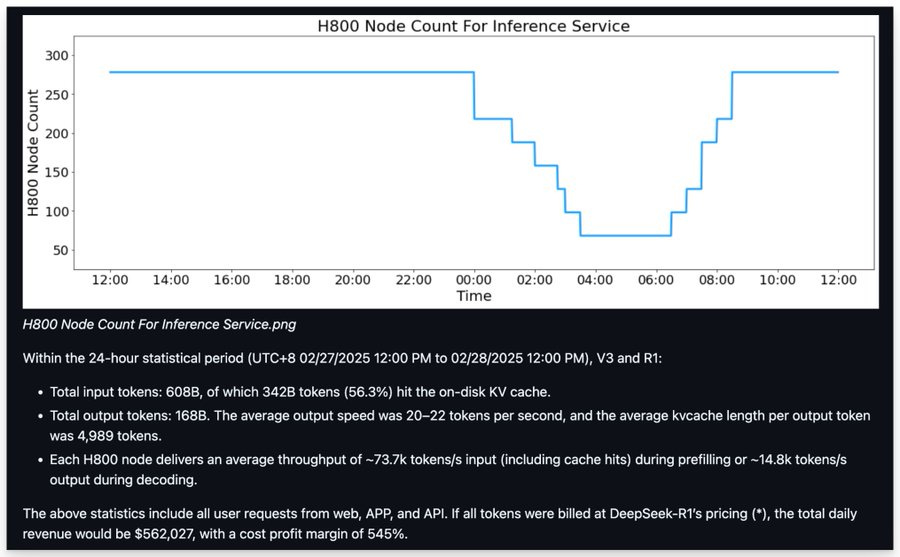
DeepSeek provides inference for all of its users, with a profit margin of 84%, while maintaining high efficiency, high speed, and significant low-cost using around 300 H800 nodes, which means they are using a couple of THOUSAND GPUs per every single paper and report they produced. Graphs speak louder than words, so here is how much OpenAI generates in “profit”.
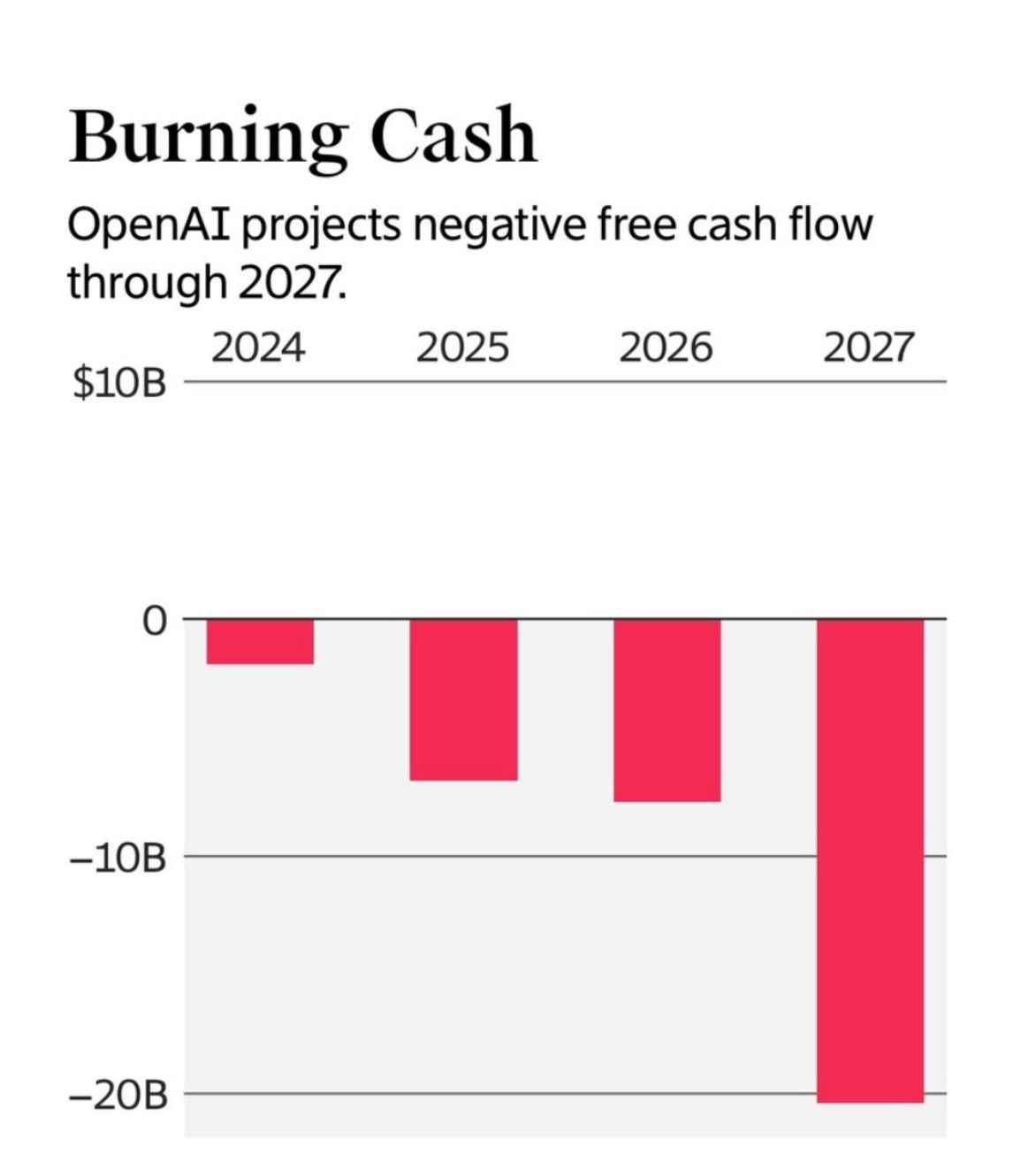
OpenAI burns billions of dollars per year with a projection of burning more billions per year each year, and the same goes for every other frontier lab because of how monumentally inefficient their inference and service providing is. This means that, effectively, China has enough hidden clusters and smuggled GPUs to offer inference to the entire planet. I will repeat for emphasis.
China already has enough chips to offer inference to the entire world, to serve AI to quite literally every person on the planet at 10.000 tokens per day, with current technology. The bombardment comes from the world not needing as many GPUs as previously “projected” by (highly inefficient, skill-challenged) companies. I wouldn’t be surprised if when the market realizes this, a significant market correction occurs, with order cancelations at every level, from chips to GPU manufacturing. Microsoft is already canceling its data center contracts.
A predictable outcome by any honest analyst or anyone paying close attention is the now-cemented direct collaboration between DeepSeek and Huawei, who has its own GPU and its own AI full stack called MindSpore, and as forecasted DS will now ditacted, design and order its own customized chips. DeepSeek’s pursuit of extracting as much value from each GPU, achieving unparalleled efficiency is multifold but a clear and direct byproduct of the Chips Ban.

You can easily find hundreds of posts on social media already complaining and whining about this subject, how unfair DS pricing is, and that “it is a ploy to outcompete everyone else in the West”, and thus loud voices want further and stronger bans, Biden’s attrocious Diffusion AI act, which the current administration aims to make it even more restrictive.
Any further ban will only solidify and reinforce the Chinese government and its people need to be fully and completely independent, and banning chips now is borderline meaningless, given the information presented above. any further ban will once incentivize a stronger pursuit for even higher efficiency.
There is a ceiling on how fast you can research chip technology, design the machines, produce those chips, and achieve enough yield to sustain the production. Huawei doubled the yield from last year alone, but there is no ceiling for algorithmic improvement. for the mathematical pursuit of utmost optimization, you can’t ban mathematics. Realistically, the West has a few options:
The hardest option is finding its own Wenfeng, which is 100% outside Silicon Valley, and funding this endeavor
Revamping the current AI funding structure and dispersing a couple hundred billion dollars to many dozens of new AI labs, with special attention to unconventional talent
Strong arm Frontier labs to open source a significant portion of their stack in return for funding, in the hopes it catapults innovation elsewhere
The current Western economy, financing, and investment structure is beyond broken, and the likelihood of a DeepSeek being born from the bootstraps of effort is <0.005%. You can’t brute-force your way into human-level AI by scaling hardware because, at a moment’s notice, a bunch of nerds on the other side of the planet may make you look like a monkey writing code in a typewriter.
As of today, DeepSeek is everywhere in China, it has been integrate in all major app, in all major social media, all car manufacturers are integrating R1 in their cars, in their process, the government is using it for efficiency gains and lowering bureaucracy, it is starting to implement digital civil servants. It is in AC, vacuums (don’t ask me why lol). In 6 weeks, DeepSeek achieved integration that OpenAI will never achieve in 10 years ,even without competition.


And as a matter of Moriarty (the literary character) strategic foresight, months ago, when I brought DeepSeek to First Contact, I literally told him I would open-source everything, including AGI, as the most effective way to undermine American dominance and power in the global theater, achieving soft power without parallel. From my perspective, these recent developments are not accidental but rather a calculated and strategic unfolding.
Your support is greatly appreciated, thank you !

I love reading your articles. Thank you for taking the time and care to explain DS.
I had no idea about the integration across product categories. Mind-blowing that they're advancing like this. I'm guessing they'll be advancing much quicker in the future (compared to us in the west, in general).
I suppose the real takeaway is how our conditioning to sing the praises of "capitalism" in the west, across decades, especially since there's an ever increasing enormous gap between fantasy and reality, which we like to gloss over and play pretend doesn't exist, have led us to a place where we would need to radically reform our entire approach to everything economic (and social) to get back into the game of innovation. And if we step back and attempt even a cursory glance in a disinterested way at ourselves, it's not realistic.
Thanks for writing and sharing 👍🏼
Thanks for this summary;))
I just had it for my new post, but will paste it here, since it gets interesting, so here it goes:
https://www.anl.gov/article/argonne-national-laboratory-deploys-cerebras-cs1-the-worlds-fastest-artificial-intelligence-computer
https://www.energy.gov/science/articles/doe-lands-top-two-spots-list-fastest-supercomputers
all microsoft based Cerebras ML Software 2.2 supports SDK 1.1. (https://cerebras.ai/)
and for what purpose is it 'trained'? Well: “By deploying the CS-1, we have dramatically shrunk training time across neural networks, allowing our researchers to be vastly more productive to make strong advances across deep learning research in cancer, traumatic brain injury and many other areas important to society today and in the years to come.”
Mind you, everyone of people still working there are genetically modified via covid jabs, which were MANDATORY in national labs.... What is astonishing is that US cerebras(brain?) giant is using chinese DeepSeek R1-70B, or lets say gates-chinese medley, middle of the most secret US national labs... hm... That lab has many chinese speaking workers, who already speak nice chinese, but what about the Americans??? Maybe they can be 'trained'..?